New analysis functionalities: Diff-in-diff and pooled panel regression
It is now possible to perform diff-in-diff analyzes using the new regress-panel-diff command. In addition, it is now permitted to run pooled panel regression.
Pooled panel regression
Linear panel regressions have until now been possible through the command regress-panel, using the alternatives fixed effects (fe), random effects (re) and between effects (be).
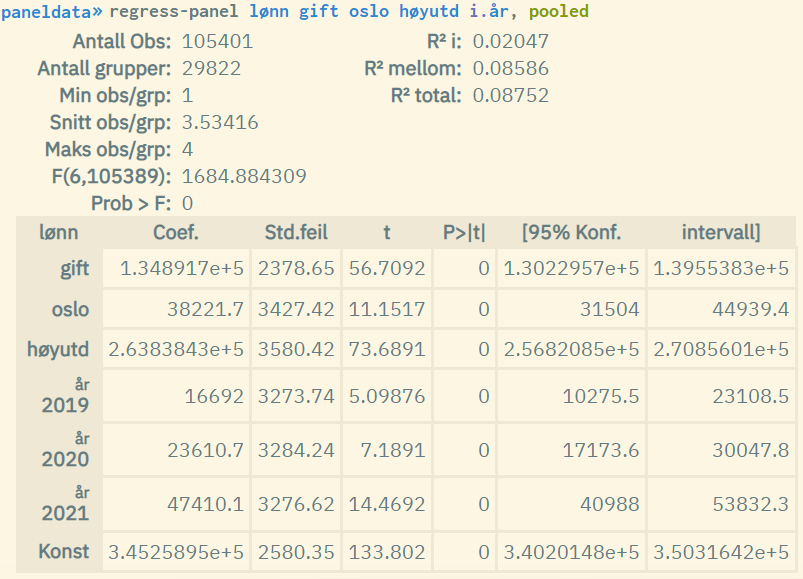
We are now introducing the new option pooled which makes it possible to run pooled panel regressions. This is equivalent to running ordinary linear regression on panel datasets, where the time dimension is disregarded (considering all observations as separate units).
Example:
Diff-in-diff
Diff-in-diff is a widely used form of analysis where the effect of a “treatment” is analyzed by comparing the change in the average value for a continuous/rankable response variable before/after the time of treatment. This is done for two groups: the treatment group and the control group. Finally, the difference between the two groups is calculated.
The following preparatory steps must be followed before running a diff-in-diff analysis:
- Create a panel dataset through the command
import-panelor by converting from “wide” format to “long” format through the commandreshape-to-long - Create a group variable with the value 1 for the treatment group and 0 for the control group
- Create a treatment variable that is set to 0 for all times before the treatment time, and 1 for all times starting from the treatment time
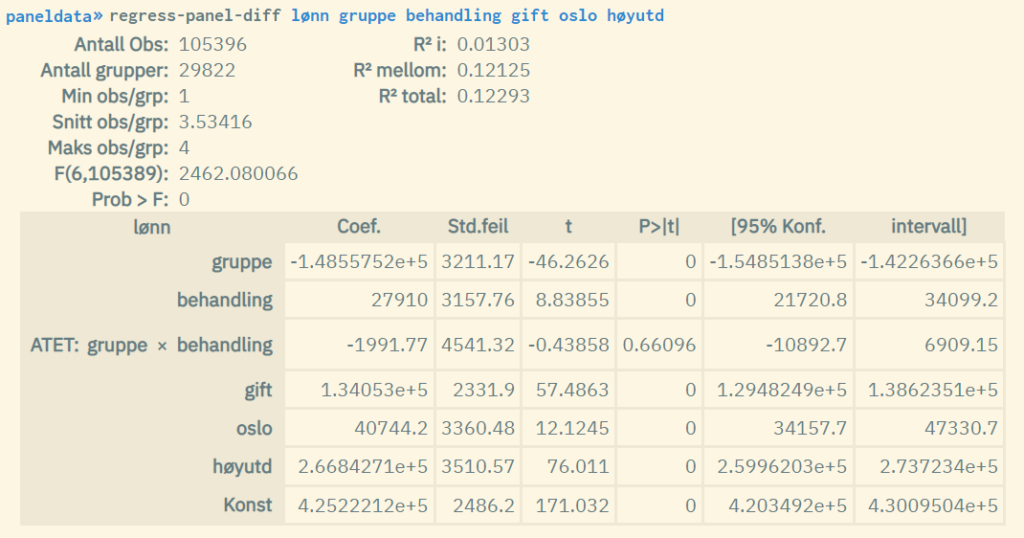
After following steps 1. – 3. the command regress-panel-diff is used.
The dependent variable is listed first. It must be continuous or rankable. The group and treatment variables need to be listed as numbers 2 and 3. This is a prerequisite for the analysis to be carried out correctly. Other independent variables are listed at the end (optional).
The result from regress-panel-diff shows a standard panel regression table with model measures and coefficient values. The diff-in-diff value (so-called ATET value – average treatment effect of the treated) corresponds to the coefficient value of the interaction term for the two dummy variables which indicate respectively group and treatment.
Example:
The command regress-panel-diff is equivalent to running regress-panel with the option pooled where the group and treatment variables are included as interaction terms as well as separate dummies (use the characters ## to express this).
Example:regress-panel-diff salary group treatment married oslo high_edu
gives the same result asregress-panel salary group##treatment married oslo high_edu, pooled
The following options are available for regress-panel-diff:
level(): Define a significance level other than the default value of 95 (5% significance level)robust: Robust standard deviationscluster(): Cluster estimation
Feel free to use the commands help regress-panel-diff and help regress-panel inside the analysis tool for more information about these new functionalities.
NB! Time (e.g. factor terms such as year) should not be included in regression-panel-diff models, as you risk obtaining 100% equal variance for the treatment variable compared with the dummy terms linked to the years from and including the time of treatment. The coefficient estimates for the variables/terms involved will then be incorrect as a result.
Click here for a link to an analysis example where a simple diff-in-diff analysis is run.
